ارسال دیدگاه
امروز: چهارشنبه , ۲۶ آذر , ۱۴۰۴
X
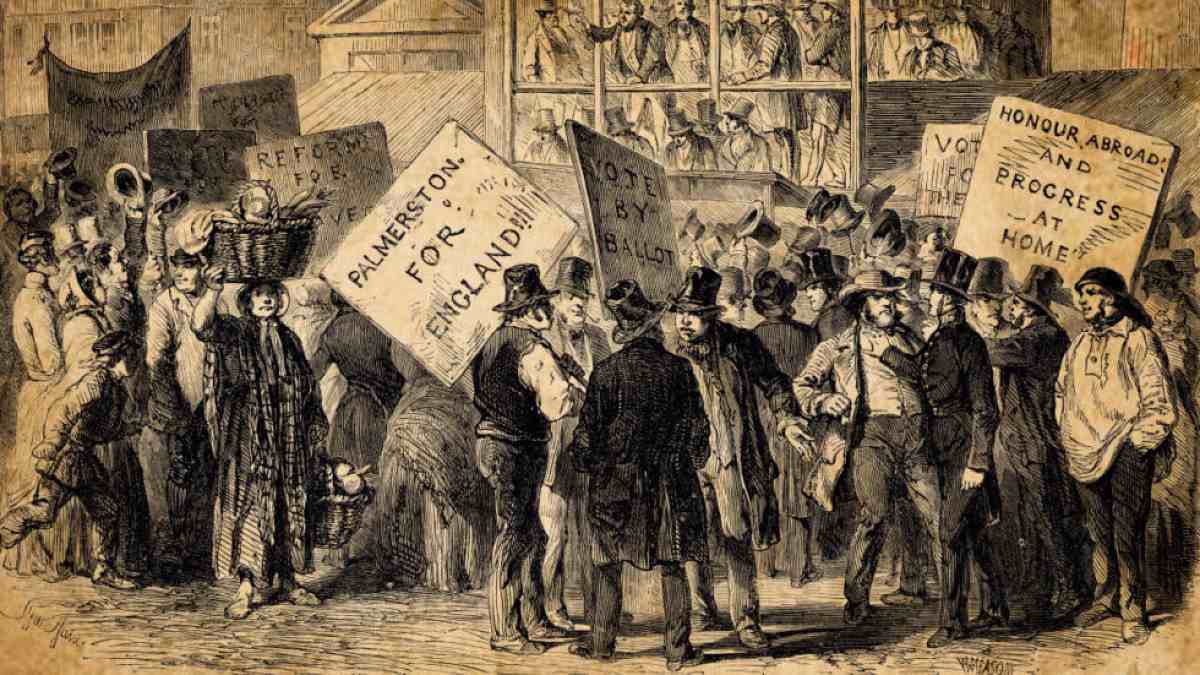
یک دانشجوی علوم کامپیوتر در آمریکا هنگام آموزش مدل هوش مصنوعی با متون ویکتوریایی، ناخواسته به کشف تاریخی واقعی رسید.

به گزارش تکراتو و به نقل از arstechnica، یک توسعهدهنده علاقهمند که در حال ساخت مدلهای زبانی هوش مصنوعی با سبک نگارشی دوران ویکتوریا بود، این هفته با شگفتی مواجه شد.
او متنی از مدل خود دریافت کرد که به اعتراضهای واقعی لندن در سال ۱۸۳۴ اشاره داشت؛ رخدادی که خودش از آن اطلاعی نداشت و پس از جستجو در اینترنت متوجه شد واقعا اتفاق افتاده است.
هایک گریگوریان، دانشجوی رشته علوم کامپیوتر در کالج مولنبرگ پنسیلوانیا، در انجمن ردیت نوشت که کنجکاو شده بود صحت این موضوع را بررسی کند و دریافت آن اعتراضها واقعا در همان سال رخ داده است.
گریگوریان در یک ماه گذشته مشغول توسعه مدلی به نام TimeCapsuleLLM بوده است؛ یک مدل زبان کوچک که صرفا بر اساس متون لندن بین سالهای ۱۸۰۰ تا ۱۸۷۵ آموزش دیده تا صدایی واقعی از دوران ویکتوریا را بازتولید کند. نتیجه این کار، تولید متنهایی پر از ارجاعات کتاب مقدسی و سبک خاص آن دوران است.
این پروژه به حوزهای نوظهور از پژوهشها میپیوندد که برخی آن را مدلهای زبانی تاریخی مینامند. برای نمونه میتوان به MonadGPT اشاره کرد که بر اساس ۱۱ هزار متن بین سالهای ۱۴۰۰ تا ۱۷۰۰ آموزش دیده یا XunziALLM که شعرهای کلاسیک چینی میسازد. چنین مدلهایی به پژوهشگران امکان میدهند با الگوهای زبانی و ذهنی گذشته تعامل کنند.
یکی از خروجیهای جالب TimeCapsuleLLM زمانی به دست آمد که گریگوریان آن را با جمله «سال ۱۸۳۴ میلادی بود» آغاز کرد. مدل ادامهای نوشت که در آن به اعتراضهای مردم لندن و حتی نام لرد پالمرستون اشاره شده بود.
وقتی او این موضوع را بررسی کرد، متوجه شد اعتراضهای گسترده در همان سال و به دنبال تصویب قانون اصلاح فقرای ۱۸۳۴ رخ داده و پالمرستون نیز در آن دوره وزیر امور خارجه بریتانیا بوده است.
آنچه این اتفاق را ویژه میکند، توانایی یک مدل کوچک و شخصی در بازسازی پیوندی واقعی از میان هزاران سند پراکنده است، بدون آنکه به طور مستقیم برای این موضوع آموزش دیده باشد. گریگوریان میگوید دادههای او تنها ۵ تا ۶ گیگابایت بوده و تصور میکند اگر این حجم به ۳۰ گیگابایت یا بیشتر برسد، نتایج بسیار جالبتری حاصل شود.
او روش خود را آموزش انتخابی زمانی مینامد و مدلها را کاملا از ابتدا با دادههای قدیمی تمرین میدهد تا اثری از زبان مدرن در خروجی نباشد. سه نسخه از مدل تاکنون ساخته شده که هر بار از نظر انسجام تاریخی بهتر شدهاند.
نسخه اولیه تنها متون بیمعنی تولید میکرد، اما نسخه ۰.۵ توانست نثر درستتری بسازد و نسخه کنونی با ۷۰۰ میلیون پارامتر حتی به رویدادهای واقعی اشاره میکند.
گریگوریان میگوید این روند باعث کاهش خطاهای خیالی مدل شده است. به گفته او نسخههای قبلی میتوانستند سبک نوشتن قرن نوزدهم را تقلید کنند اما وقایع ساختگی میساختند، در حالی که نسخه جدید شروع به یادآوری دادههای واقعی کرده است.
این نوع آزمایشها میتواند برای پژوهشگران تاریخ و علوم انسانی دیجیتال سودمند باشد، زیرا امکان گفتگو با مدلهای زبانی شبیه به گویشها و سبکهای گذشته را فراهم میکند. هرچند ممکن است خروجی همیشه دقیق نباشد، اما برای مطالعه نحو و واژگان قدیمی الهامبخش خواهد بود.
گریگوریان قصد دارد در آینده مدلهایی برای شهرهای دیگر مانند پکن، مسکو یا دهلی نیز توسعه دهد و کدها و نتایج خود را به صورت عمومی در گیتهاب منتشر کرده است.
در دنیایی که معمولا از خطاهای خیالی هوش مصنوعی صحبت میشود، این بار خروجی ناخواسته درست مدل او نوعی واقعیت اتفاقی به حساب میآید.
دانلود آهنگ
دیدگاهتان را بنویسید